The complexity of Optical Character Recognition as a problem isn’t always fully understood by users. In 1999, Stephen V. Rice, George Nagy and Thomas A. Nartker offered an illustrated guide to OCR that suggested “A seven year old child can identify characters with far greater accuracy than the leading OCR systems” (165). While the technology has improved over the last twenty years, there are still ongoing issues such as certain kinds of font and typeface.

The Trove website has an insightful guide to OCR for newspapers, which summarises the factors that influence OCR quality. The central concern is the quality of the physical object and the microfilm, as many digitisers have historically used microfilming as an intermediary step. These problems shaped early digitised newspaper collections: initial selection was usually based on having full print runs of appropriate quality due to the requirements of the OCR, and the lessons learned during those early projects, in turn, shaped the processes and metadata structures of subsequent digitised newspaper collections.
As our metadata map reflects, OCR is a complex process with several steps, not just recognition of individual letters and words, and consequently there are many metadata fields containing OCR information. What is sometimes referred to as Optical Layout Recognition (or document layout analysis) is particularly important for newspapers in recognising structural features such as headlines, columns and images. Because the quality of the source image is so important, pre-processing steps optimise the scanned page image. This might include skew correction, scaling of the image and noise reduction, among other things. Post-processing involves correcting errors. Usually a confidence level is also produced. The steps are demonstrated in this diagram from the OCR-D project, which is leading exciting new research in this area:
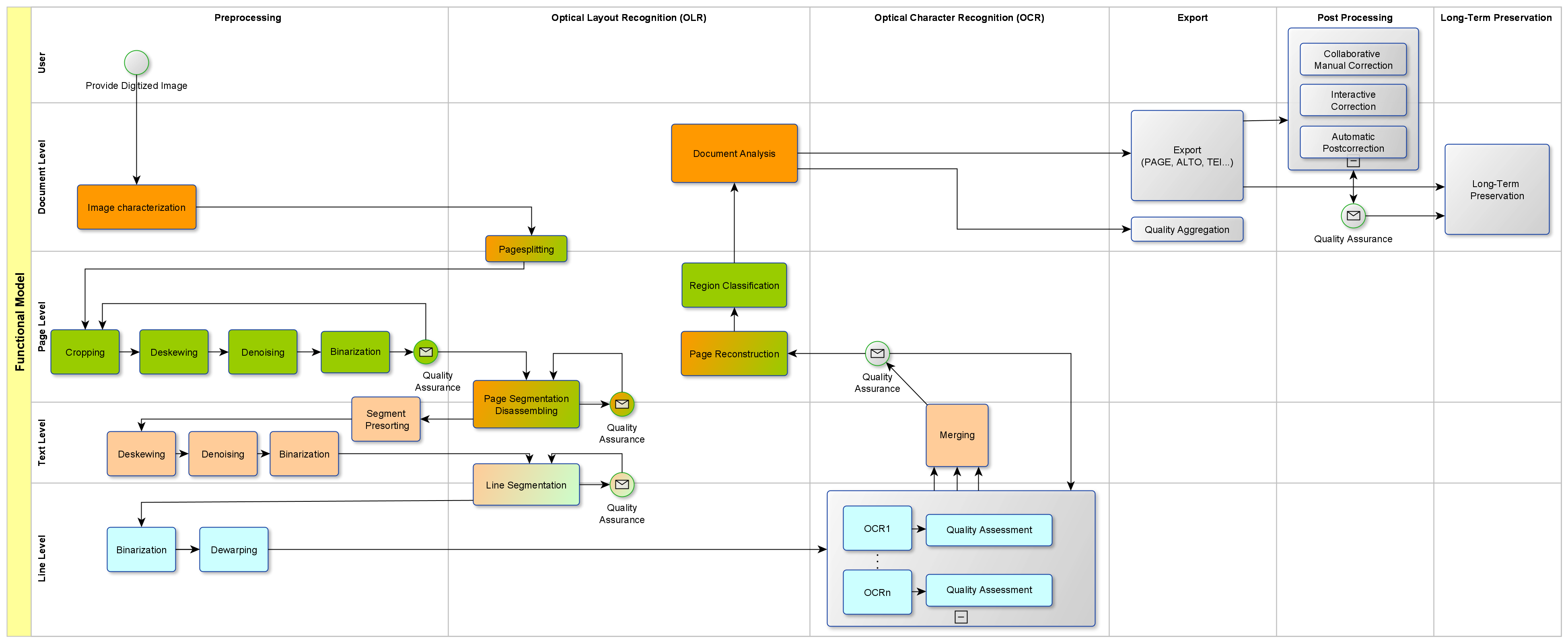
The changing layout of newspapers over the nineteenth century complicates the OCR process. OCR includes neural networks and AI techniques that are trained on samples, but there is so much variation between individual titles and over time that it’s challenging for the software to cope with. It’s difficult to convey these shifting elements, such as the fact that headlines were introduced late in the period and were not universally adopted.
OCR is thus an ongoing issue for digitisers and librarians. In recent conversations with members of a project attempting to aggregate several different newspaper collections, they mentioned that they specifically looked in the metadata provided to them for which OCR software was used, because they had found an older version of the software to be more reliable. Being able to trace what software version was used, or the date the OCR took place, therefore makes a difference, and the considerations of OCR have had a knock-on effect on the shape and structure of collections.
But how do we solve these problems? As we will discuss in future blog posts, one answer to this is to crowdsource text and layout correction, as Trove have done very effectively. The continued improvement of machine learning also constantly brings us closer to solving these problems. In the meantime, knowing what OCR is used, reflecting on the quality of the physical object, and understanding how these elements shape not only the article or page in front of you but also the shape and structure of the collection itself, are critical for researchers working with digitised newspaper collections.
Bibliography
Gupta, Brijesh. “Improve Accuracy of OCR using Image Preprocessing.” Medium, 11 September 2018. https://medium.com/cashify-engineering/improve-accuracy-of-ocr-using-image-preprocessing-8df29ec3a033.
Koistinen, Mika, Kimmo Kettunen and Jukka Kervinen. “How to Improve Optical Character Recognition of Historical Finnish Newspapers Using Open Source Tesseract OCR Engine.” 8th Language & Technology Conference: Human Language Technologies as a Challenge for Computer Science and Linguistics, 2017. https://www.researchgate.net/publication/321133967_How_to_Improve_Optical_Character_Recognition_of_Historical_Finnish_Newspapers_Using_Open_Source_Tesseract_OCR_Engine. Accessed 21 February 2020.
“Optical Character Recognition (OCR) on Newspapers.” Trove Help Centre. National Library of Australia, 2019. Web. https://help.nla.gov.au/trove/for-digitisation-partners/optical-character-recognition-ocr-newspapers. Accessed 21 February 2020.
Rice, Stephen V., George Nagy and Thomas A. Nartker. Optical Character Recognition: An Illustrated Guide to the Frontier. Springer, 1999.